Understanding when a useful feature, such as Adaptive Execution Plans, would fire is of crucial importance for the stability of any DB system.
There are a few documents explaining how this feature works, including some that dig deep into the details:
http://kerryosborne.oracle-guy.com/2013/11/12c-adaptive-optimization-part-1/
http://www.dbi-services.com/index.php/blog/entry/oracle-12c-adaptive-plan-inflexion-point
http://scn.sap.com/community/oracle/blog/2013/09/24/oracle-db-optimizer-part-vii–looking-under-the-hood-of-adaptive-query-optimization-adaptive-plans-oracle-12c
However, I was not able to find a comprehensive technical document about when this feature fires.
My previous post included some general thoughts about issue. The simple explanations there, while plausible in general, do not fully match the messy reality.
I this post I will try to identify when a SQL plan goes from non-Adaptive (NL/HJ) to Adaptive and back. Once I have the “switching” point, I’ll review the 10053 trace just before and just after the switch.
Tables T1 andT2 was created this script. T2 has 1 million records and T1 has one.
In a loop, I insert a single record into T1 and run this query:
select t2.id ,
t1.str,
t2.other
from
t1,
t2
where
t1.id = t2.id
and t1.num = 5
and <UNIQUE NUMBER> = <UNIQUE NUMBER > ( insure that there is no plan reuse)
Initially the SQL uses Nested Loops, but after inserting 5 or 6 records, it switched to an Adaptive Execution Plan. We have a “switch” point!!!
The 10053 trace for the Non-Adaptive (NL) plan looks like this:
—————————————————————————————
Searching for inflection point (join #1) between 1.00 and 139810.13
AP: Computing costs for inflection point at min value 1.00
..
DP: Costing Nested Loops Join for inflection point at card 1.00
…
NL Join : Cost: 5.00 Resp: 5.00 Degree: 1
..
DP: Costing Hash Join for inflection point at card 1.00
….
Hash join: Resc: 135782.55 Resp: 135782.55 [multiMatchCost=0.00]
….
DP: Costing Nested Loops Join for inflection point at card 139810.13
….
NL Join : Cost: 279679.55 Resp: 279679.55 Degree: 1
..
P: Costing Hash Join for inflection point at card 139810.13
….
Hash join: Resc: 290527.15 Resp: 290527.15 [multiMatchCost=0.00]
DP: Found point of inflection for NLJ vs. HJ: card = -1.00
——————————————————————————————————–
The 10053 trace for the Adaptive plan looks like this:
——————————————————————————————————–
Searching for inflection point (join #1) between 1.00 and 155344.59
+++++
DP: Costing Nested Loops Join for inflection point at card 1.00
…
NL Join : Cost: 5.00 Resp: 5.00 Degree: 1
….
DP: Costing Hash Join for inflection point at card 1.00
…
Hash join: Resc: 135782.55 Resp: 135782.55 [multiMatchCost=0.00]
+++++
DP: Costing Nested Loops Join for inflection point at card 155344.59
….
NL Join : Cost: 310755.84 Resp: 310755.84 Degree: 1
….
DP: Costing Hash Join for inflection point at card 155344.59
..
Hash join: Resc: 290536.21 Resp: 290536.21 [multiMatchCost=0.00]
+++++
DP: Costing Nested Loops Join for inflection point at card 77672.80
…
NL Join : Cost: 155380.42 Resp: 155380.42 Degree: 1
…
DP: Costing Hash Join for inflection point at card 77672.80
…
Hash join: Resc: 290392.89 Resp: 290392.89 [multiMatchCost=0.00]
+++++
DP: Costing Nested Loops Join for inflection point at card 116508.69
…
NL Join : Cost: 233068.13 Resp: 233068.13 Degree: 1
…
DP: Costing Hash Join for inflection point at card 116508.69
…
Hash join: Resc: 290464.05 Resp: 290464.05 [multiMatchCost=0.00]
+++++
DP: Costing Nested Loops Join for inflection point at card 135926.64
…
NL Join : Cost: 271911.98 Resp: 271911.98 Degree: 1
…
DP: Costing Hash Join for inflection point at card 135926.64
…
Hash join: Resc: 290500.13 Resp: 290500.13 [multiMatchCost=0.00]
+++++
(skiped iterations)
DP: Found point of inflection for NLJ vs. HJ: card = 145228.51
——————————————————————————————————–
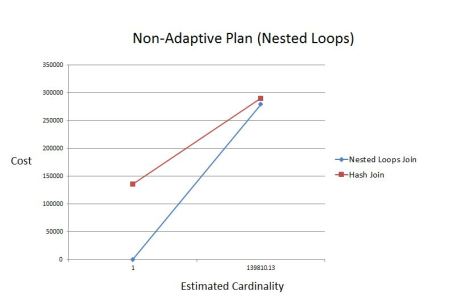
The relationship between cardinality and cost for the non-adaptive plan (NL) is shown here:
The respective graphic for adaptive plan is here:
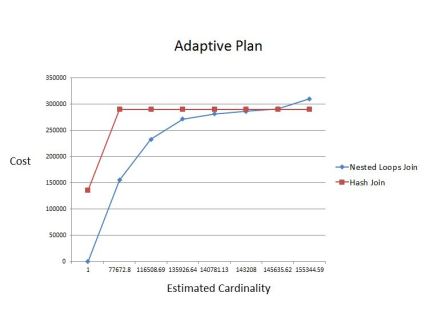
In this situation, Oracle went with an adaptive plan because it was able to find an inflection point.
One important factor that determines whether an inflection point is found is the range the inflection point is searched in. That is, the main reason the CBO could not find an inflection point for the non-adaptive plan is that the range was from 1 to 139810. If the range was wider, it would have probably found an inflection point.
That means that in some cases the decision to use adaptive plans depends on what cardinality range it would use when searching for the inflection point.
It should also be noted that there are situations where Oracle would decide not to use adaptive plans without going through the motions of looking for an inflection point.
All in all, lots of additional research is needed to answer those questions…



 Posted by iiotzov
Posted by iiotzov 

